
Dzisiaj byliśmy na wykładzie „Wprowadzenie do języka Scala” autorstwa Arkadiusza Burdacha prowadzonym w ramach Jinkubatora na MIM UW. Język Scala coraz częściej pojawia się w środowisku Javowym, więc postanowiłem zapoznać się z nim w przystępnej formie, jaką na ogół oferują „Jinkubatory”.

Prowadzący jest pracownikiem firmy touk.pl, na wstępie zaznaczył że to właśnie tam prowadzone są trzy projekty w Scali od trzech lat.
Wybór języka Scala jako następcy Javy został uzasadniony przede wszystkim pozytywnymi emocjami, a ponadto:
- dostępnością REPL (ale w Javie jest, o czym dowiedziałem się dopiero dziś :))
- składnią:
– inferencja typów
– brak średników
– wszystko jest wyrażeniem
– nie trzeba pisać return
– deklaratywne programowanie - spójność (Java mimo dynamicznego rozwoju ma wiele zaszłości do zachowania wstecznej kompatybilności)
– dziedziczenie z scala.Any na scala.AnyVal (bez null) i scala.AnyRef
– dostęp do pól jest polimorficzny (w przeciwieństwie do Javy)
– nie ma pól ani metod statycznych
– konstruktor jednocześnie deklaruje definicje pól klasy, a alternatywne konstruktory robi się przez fabryki
– dla parametrów można deklarować domyślną wartość
– metody można wywoływać w parametrami w innej kolejności niż zadeklarowana, tylko wtedy trzeba podawać ich nazwy, np. „foo(b = 1, a = 2)”
– metoda deklaruje się przez „def”, funkcje przez określenie co przyjmuje i co zwraca (bez słowa kluczowego)
– w scali jest mniej składników języka: klasy, zachowania (trait), obiekty, stałe, zmienne, metody, importy - bezpieczeństwo: statyczne typowanie, zwięzły zapis, niemutowalne kolekcje, łatwe kopiowanie obiektów, programowanie bez null
– „case class” daje metodę „copy”, która umożliwia tworzenie obiektów niemutowalnych (w Javie trzeba robić kopię ręcznie)
– val/var – rozróżnienie czy pole jest zmienną czy stałą
– Option-ale – pudełka które umożliwiają sprawdzanie czy coś jest zdefiniowane – kompilator pilnuje jak odwołujemy się do pól oznaczonych jako Option i czy są poprawnie obsłużone. Jak przekazujemy do optionala, to opakowujemy przez „Some(„xxx”)” albo przez „None” - ekspresyjność:
– deklaratywne programowanie
– opcjonalne: kropki, nawiasy, nawiasy klamrowe w metodach z jednym wyrażeniem
– „implicit class”: np. daje możliwość: 3.timer { println(„work”)} – sprawdzane w czasie kompilacji (w przeciwieństwie do groove’go)
– trait (zachowania) – interfejsy dające możliwość definiowania metod (zachowań) – coś jak klasa abstrakcyjna ale nie wymagająca konstruowania obiektów umożliwiające wielokrotne dziedziczenie – ja to na razie rozumiem raczej jako wywołanie metod statycznych
– pattern matching: „switch na sterydach”
Prowadzący przyjął ciekawą koncepcję porównywania odpowiedników kodu w Javie i Scali przy pomocy konsoli REPL – pomysł trudny i ambitny ale przeprowadzony z „prawie sukcesem”. Fajne, bo było widać live-coding i co faktycznie polecenia robią, widać było też błędy (zamierzone i nie…). Problemem był z kolei mały ekran i wielka czcionka, co sprawiało że przy większych fragmentach kodu część po prostu znikała. Niemniej jednak podstawy teoretyczne zostały pokazane bardzo fajnie.
W ramach samego wykładu zabrakło mi trochę „praktyki”, tzn. tego wszystkiego co sprawia że język jest używalny w realnych projektach: IDE, frameworki, OR-mapping, itp. Prawdopodobnie inni słuchacze mieli podobne odczucia, bo tego dotyczyły pierwsze pytania po wykładzie. Prowadzący starał się wyjaśniać te wątpliwości i tak dowiedzieliśmy się że:
– IDE: Scala IDE czyli Eclipse, IntelliJ IDEA oraz NetBeans IDE z pluginami do Scali
– frameworki webowe: Play (podobny do RoR), Lift (podobny do PHP – view first) i Spray.
– budowanie projektów: SBT (jak Gradle)
– or-mapping: Slick,, Squeryl
– biblioteki: ScalaUtils, scalaz, shapeless, ScalaTest, ScalaCheck.
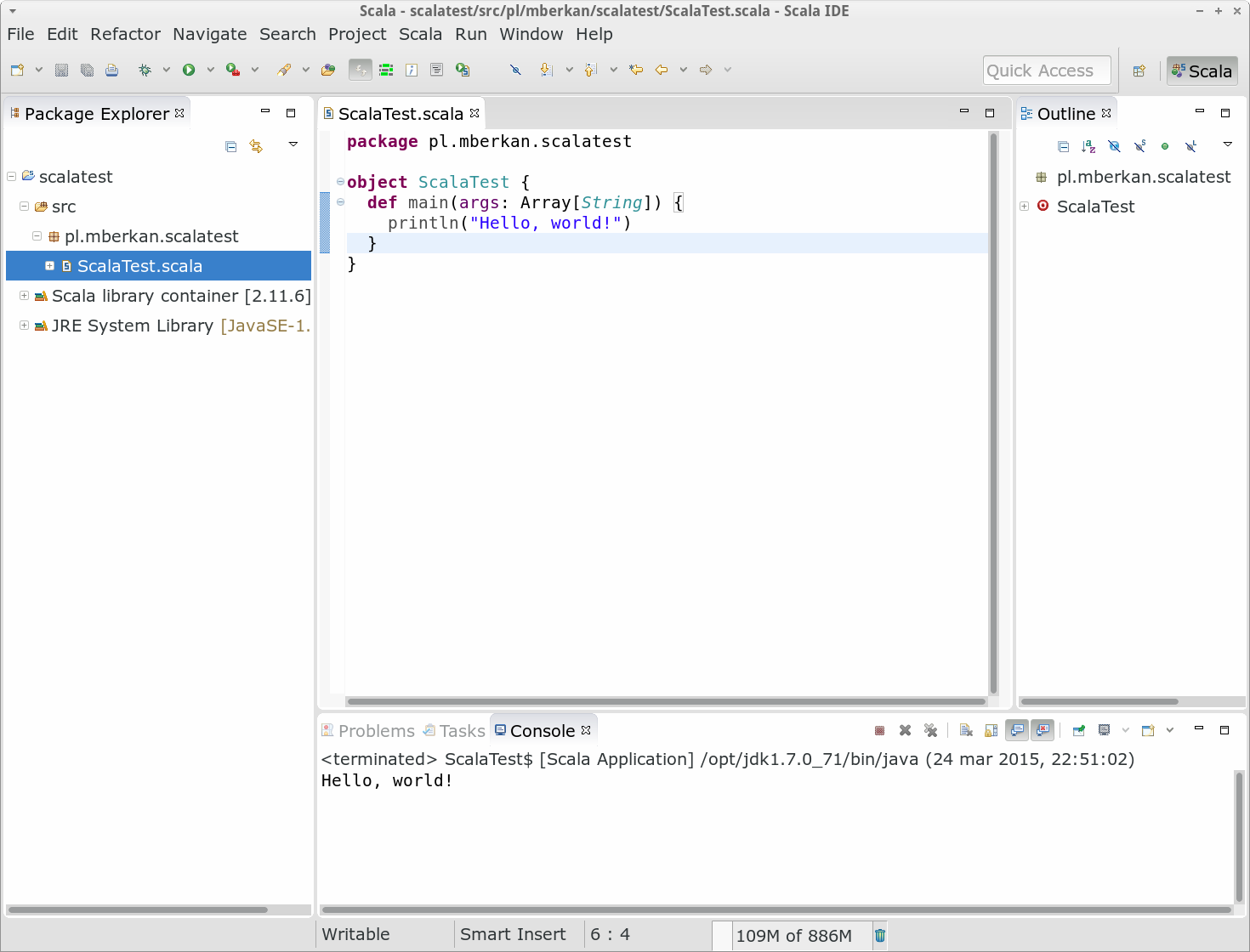
Żeby sprawdzić czy i jak to w ogóle działa, uruchomiłem sobie lokalnie Scala IDE z przykładowym Hello World i działa – pierwsze starcie zaliczone 🙂
O autorze
Marek Berkan: programista, entuzjasta tworzenia oprogramowania, zarządzania zespołami technicznymi. Prywatnie motocyklista, kolarz MTB, biegacz, żeglarz, rekreacyjny wspinacz, zamiłowany turysta. Witryny: google plus, facebook, twitter.
- More at
