
Może część z Was zajmująca się HTML’em, zadała sobie trud przeczytania specyfikacji tego języka i zauważyła że głównym znaczniku html jest możliwość umieszczenia atrybutu lang. Ja o tym wiedziałem ale nigdy nie wiedziałem do czego może on w praktyce służyć. I dowiedziałem się dopiero w tym miesiącu, po 16 latach korzystania z HTML (tak, tak, pierwszy napisany website www.7nfi.com.pl w 1998…).
W praktyce powinno wyglądać to tak:
<html lang="pl"> ... </html>
Otóż okazało się że z tej informacji może korzystać przeglądarka do zmieniania wielkości liter, np. do „uppercase” przy pomocy CSS (styli).
Poniższy kod wyrenderuje nam jako wynik testu z małej litery „i” dużą literę „I”:
<html>
<body>
<p>Test:
<span style="text-transform:uppercase;">i</span>
</p>
</body>
</html>

Kłopot zaczyna się wtedy gdy używamy innego języka niż polski czy angielski, np. turecki. Okazało się że w nim duża litera „i” to wcale nie jest „I” tylko „İ” (z kropką na górze, U+0130). Natomiast duże „I” bez kropki to jest duża wersja małego „ı” (małe i bez kropki, U+0131). Poniższa tabelka ze strony prezentuje obydwie litery w dużej i małej wersji:
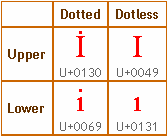
Nieźle, nie?
Jeżeli o tym nie wiemy (jak ja dotychczas), to poprawne słowo napisane małymi literami zamienione stylami na duże, staje się „trochę innym” słowem, ale dla Turka będzie to słowo błędne. Dopiero poinformowanie przeglądarki, że strona jest w języku tureckim powoduje, że uppercase zaczyna działać dobrze:
<html lang="tr">
<body>
<p>Test:
<span style="text-transform:uppercase;">i</span>
</p>
</body>
</html>
![]()
O autorze
Marek Berkan: programista, entuzjasta tworzenia oprogramowania, zarządzania zespołami technicznymi. Prywatnie motocyklista, kolarz MTB, biegacz, żeglarz, rekreacyjny wspinacz, zamiłowany turysta. Witryny: google plus, facebook, twitter.
- More at

Od kolegi który zajmuje się tematem lokalizacji aplikacji na inne języki dostałem jeszcze jednego ciekawego newsa, którego cytuję:
W praktyce powinno być:
zgodnie ze standardem.