

Dwa lata temu pisałem o pojęciu Software Craftsmanship i książce Sandro Mancuso która opisuje to pojęcie. Wtedy było dla mnie jeszcze nieco abstrakcyjne, więc nie opisałem praktycznych przykładów z własnego doświadczenia. Ostatnio, dzięki dołączeniu do istniejącego zespołu utrzymaniowego, miałem możliwość weryfikacji „rzemieślniczego” podejścia do używanych narzędzi i organizacji pracy. Specyfika pracy przy ponad 10 projektach w różnych fazach życia, z których najstarszy działa nieprzerwanie od 2005 (!) roku, wymaga od zespołu bardzo zdyscyplinowanego podejścia. W tym wpisie przedstawię 15 elementów które powinny być przestrzegane aby zespół techniczny sprawnie pracował.
Zapewne każdemu programiście ze stażem 5y+ zdarzył się dołączyć do projektu w fazie utrzymania. Taki projekt już działa produkcyjnie, są rozwiązane problemy „wieku dziecięcego”, zlecane są tylko nieregularnie doraźne zmiany. Zdarzyło mi się słyszeć w czasie spotkań rekrutacyjnych od kandydatów przychodzących do naszej firmy, że odchodzili z poprzednich zespołów bo nie pracował tam już nikt kto uczestniczył w implementacji ani pamiętający szczegółowe założenia techniczne, ponadto brakowało jakiejkolwiek dokumentacji. Przez to praca tam była bardzo nieefektywna lub praktycznie niemożliwa.
W największym skrócie, aby efektywnie pracować w projekcie, a także z czystym sumieniem przekazać go swoim następcom, trzeba zadbać o kilkanaście relatywnie prostych aspektów:
- Przygotowanie i utrzymanie podstawowej dokumentacji.
- Jasny podział ról i obowiązków z zespole i poza nim.
- Stosowanie praktyki wzajemnych przeglądów kodu (ang. Code Review).
- Używanie narzędzia do statycznej analizy kodu.
- Utrzymywanie środowisk przed-produkcyjnych.
- Przestrzeganie procedury releasów i instalacji nowych wersji aplikacji.
- Monitorowanie parametrów środowisk produkcyjnych.
- Analiza logów ze środowisk produkcyjnych.
- Dbanie o dane testowe używane w środowisku developerskim.
- Utrzymanie procedur testów automatycznych.
- Organizacja prac i spotkań zespołu w oparciu o współdzielony kalendarz.
- Przestrzeganie zasad komunikacji w zespole.
- Ustalenie i dbanie o harmonogram pielęgnacji i unowocześniania stosu technicznego.
- Stosowanie procedury przyjęcia nowego członka zespołu.
- Wykonywanie cyklicznych spotkań okresowych w zespole.
Jeżeli w projekcie w którym pracujesz powyższe zasady są znane i przestrzegane, to jesteś szczęściarzem i tutaj możesz zakończyć czytanie tego wpisu. Jeżeli jednak któreś z tych punktów nie są przestrzegane albo – co gorsza – nie wiesz co znaczą, to zachęcam do dalszej lektury.
1. Podstawowa dokumentacja
Każdy ukończony projekt powinien być opisany przez podstawą dokumentację, na którą składają się:
- podstawowe informacje o projekcie: nazwa, odnośniki do repozytorium kodu i systemu zarządzania zadaniami (np. Jira), zestawienie istniejących środowisk itp.,
- podręcznik developera – instrukcja jak po pobraniu kodu źródłowego uruchomić lokalnie aplikacje i móc rozpocząć wprowadzanie zmian,
- procedury aktualizacji poszczególnych środowisk opisujące krok po kroku jak po wprowadzeniu zmiany do repozytorium spowodować żeby nowa wersja aplikacji została zainstalowana w środowisku produkcyjnym,
- rejestry aktualizacji środowisk – zestawienie wykonanych instalacji na poszczególne środowiska,
- zakres i opis wykonanej implementacji albo dostosowania gotowej platformy – ogólny obraz tego co i po co programiści zaimplementowali,
- zestawienie integracji z systemami zewnętrznymi: przeznaczenie biznesowe, formaty danych, kanały komunikacji, częstość wywołań, wskazanie do miejsc w kodzie implementujących logikę po stronie naszej aplikacji.
2. Osoby w zespole/projekcie i zakres odpowiedzialności
Żeby projekt mógł posuwać się do przodu, wszystkim członkom zespołu potrzebna jest wiedza o rolach innych osób w tym projekcie – zarówno aktualnie w nim pracujących, jak i takich które nie pracują już w projekcie albo w ogóle w firmie. Zaskakująco wartościowa (choć niekoniecznie pozytywna…) jest ta ostatnia informacja, bo dla mnie osobiście jest to motywacja do „prac archeologicznych” z założeniem tworzenia przy tej okazji nowej dokumentacji, tak aby moim następcom było już łatwiej. Tym samym staję się „ojcem chrzestnym” osieroconego kodu.
Do posiadania decyzyjności ważne jest zidentyfikowanie ról poza zespołem, tzn.:
- product / project / business owner – osoba ustalająca cele i priorytety projektu i składających się na niego zadań,
- project manager – osoba odpowiedzialna za harmonogram prac, kalendarz wydawania wersji, komunikacje z klientem itp.
Z kolei aby móc sprawnie ustalać szczegóły i rozdzielać zadania, musimy wiedzieć kto dla danego projektu jest (lub był):
- architektem – analizował wymagania, ustalał podstawowe założenia,
- lider techniczny – ustalał szczegóły techniczne, rozwiązywał trudniejsze problemy.
Żeby sprawnie prowadzić prace ważne jest określenie zakresu odpowiedzialności pomiędzy poszczególnymi członkami zespołu (np. programiści, front-end developerzy, testerzy) oraz zasad współpracy ze światem zewnętrznym. Najwygodniej zrobić to spisanymi kontraktami znanymi z metodyki SCRUM jako:
- Definition of Ready (DoR) – wymagania dotyczące zadań wchodzących do realizacji do zespołu, np. precyzyjnego opisania „user story”, szczegółów integracji, dostarczenia makiet lub projektów graficznych, opisania scenariuszy testów akceptacyjnych, itp.
- Definition of Done (DoD) – wymagania dotyczące zadań wychodzących z zespołu do klienta, np. przechodzące testy jednostkowe i integracyjne, dostarczone dane testowe i skrypty migracyjne do zmian modelu bazy danych, brak ostrzeżeń ze statycznej analizy kodu, zweryfikowane scenariusze testów akceptacyjnych, brak błędów regresji w innych obszarach, nie gorsza wydajność, itp.
3. Praktyka Code Review
O wartości wzajemnego przeglądania kodu przed dodaniem go do wspólnego repozytorim napisano wiele opracowań – zasadności tego podejścia chyba nikt nie podważa. Skracając, takie podejście ma dwie główne zalety:
- programista wiedząc że zaraz ktoś będzie (uważnie) czytać jego kod bardziej się przykłada, w efekcie nie są przepuszczane bezkrytycznie rozwiązania „tymczasowe”, „na szybko” , „może zadziała”, itp.
- druga osoba czytająca kod musi zrozumieć sens biznesowy i założenia techniczne wykonywanej zmiany, przez co zespół naturalnie wymienia się wiedzą, w efekcie nie powstają „silosy” typu „na tym module zna się tylko Abacki, ale on jest na urlopie, więc wykonamy tą zmianę dopiero za miesiąc – jak wróci”.
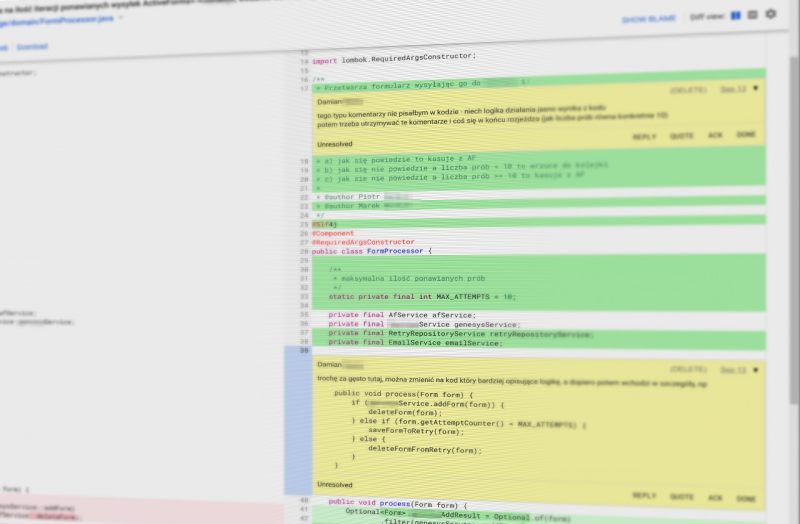
4. Statyczna analiza kodu
Współczesne narzędzia do analizy kodu umożliwiają znalezienie błędów jeszcze zanim kod zostanie uruchomiony. Wiodące środowiska programistyczne (czytaj: IntelliJ Idea) mają taką kontrolę wbudowaną, więc błędy są podświetlane od razu po napisaniu linijki kodu lub zamknięciu bloku. Jednak dobrą praktyką jest używanie scentralizowanego narzędzia typu SonarQube, które np. raz na dobę analizuje cały kod.
Zaletami takiego rozwiązania są:
- wstępna klasyfikacja ważności problemu,
- zarządzanie procesem (statusami) rozwiązywania problemu,
- przypisanie problemu do konkretnej osoby,
- zgrubne oszacowanie czasochłonności naprawy,
- analizy czasowe, tzn. prezentacja tendencji: czy ilość problemów maleje czy wzrasta w zadanym okresie.
Żeby statyczna analiza kodu miała wartość, to zespół musi w zdyscyplinowany sposób pilnować aby błędy naprawiać na bieżąco. Dobrą praktyką jest wpisanie polityki „zero odstępstw” w kontakt „Definition of Done” i codzienne zaczynanie pracy od naprawy własnych błędów znalezionych w dniu poprzednim.
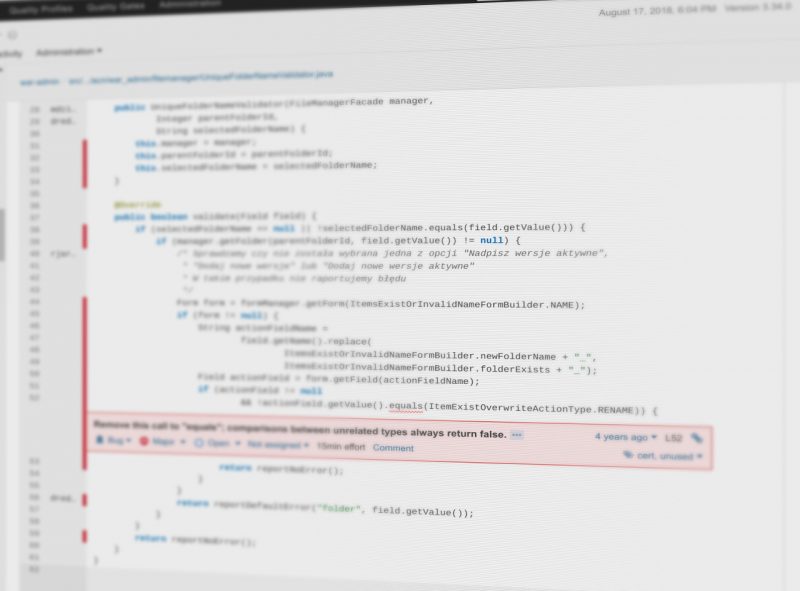
5. Środowiska przed-produkcyjne
Każda nowa wersja aplikacji przed uruchomieniem w środowisku produkcyjnym powinna być zweryfikowana na środowisku testowym. W zależności od dynamiki i fazy projektu najczęściej spotyka się następujące środowiska:
- CI (Continous Integration) – wewnętrzne testy automatyczne (np. raz na dobę),
- IMP (Implementation) / TEST (Testing) – testowanie rozwojów,
- STG (Staging) – kopia środowiska produkcyjnego do odtwarzania błędów serwisowych.
Ze środowiskami testowymi, w szczególności w projektach utrzymaniowych, są związane dwa wyzwania (żeby nie nazywać „problemy”):
- ich aktualizacja powinna być możliwe zautomatyzowana i niezależna od lokalnego środowiska developerskiego poszczególnych członków zespołu, tzn. najlepiej jakby budowanie wersji i aktualizacja była wykonywana na dedykowanym serwerze „Continous Delivery” (np. Jenkins). Unikamy w ten sposób sytuacji że „u Abackiego zawsze się budowało”, a u innych osób są problemy z wersjami zależnych bibliotek, narzędzi budujących, jakieś niejawne zależności od systemu operacyjnego, itp.
- rzadko używane środowiska testowe potrafią się starzeć, wyłączać, a nawet znikać, więc gdy przychodzi potrzeba wykonania pilnej aktualizacji to okazuje się że jest to duży problem. Dobrą praktyką jest cykliczne wykonywanie aktualizacji dla weryfikacji czy wszystko nadal działa.

6. Procedura release i instalacji nowej wersji aplikacji
Aby sprawnie instalować nowe wersje aplikacji warto rozpisać kroki, role i odpowiedzialności poszczególnych osób biorących dział w takim procesie, np. lider techniczny, manager, tester, dyżurny programista.
Drugą sprawą jest zaplanowany harmonogram poszczególnych releasów, w szczególności jeżeli są cyklicznie powtarzalne – dzięki temu można z wyprzedzeniem zaplanować kto się tym zajmie, kiedy będą trwały testy wewnętrzne i testy klienta oraz zachować bufor czasu na wprowadzanie ewentualnych poprawek.
Kolejną sprawą jest ustalenie spójnej konwencji nazewniczej branchy i numerów wersji w repozytorium, tak aby przegląd historii i wydawanie nowych wersji były dla wszystkich oczywiste.
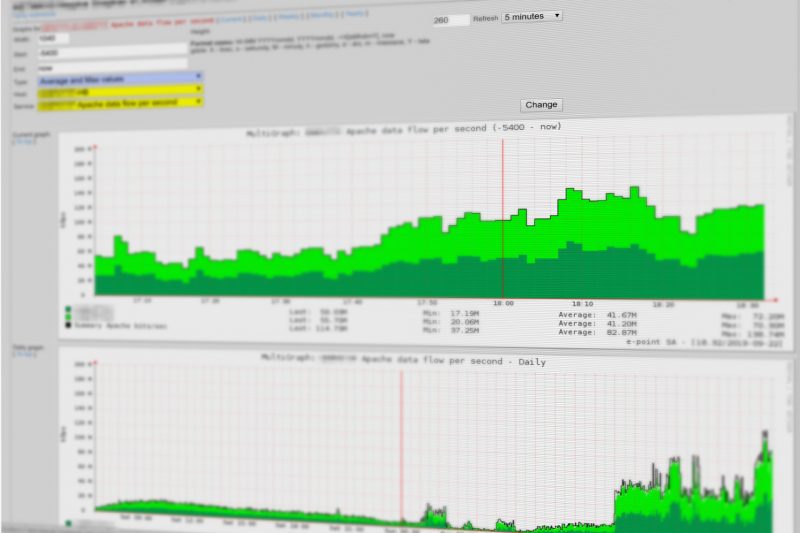
7. Monitoring parametrów środowiska PROD
Aby z wyprzedzeniem zapobiegać problemom system produkcyjny musi być monitorowany. Oprócz oczywistych parametrów systemów operacyjnych jak zużycie procesora, pamięci i dysków, bardzo ważne jest monitorowanie dokładniejszych parametrów baz danych i serwerów aplikacyjnych, co w przypadku systemów opartych na mikrousługach jest ilościowo jeszcze bardziej złożone.
Oprócz samego mierzenia parametrów i wizualizacji w postaci wykresów, ważne jest ustawienie odpowiednich automatycznych ostrzeżeń wysyłających informacje do zespołu gdy parametry przekroczą zadaną wartość i konieczna jest pilna analiza problemu.
8. Analiza logów
Poprawnie wykonane oprogramowanie loguje zdarzenia diagnostyczne do plików logów. Zanim dojdzie do awarii, w logach najczęściej są umieszczane ostrzeżenia, których czytanie możę pozwalić takim awariom zapobiegać. Czytanie takich logów umożliwia też szybsze zidentyfikowanie problemów widocznych w postaci błędów typu „500 Server Error”, zanim użytkownicy zaczną dzwonić do działu obsługi klienta.
Najczęstsze obszary analizy to:
- logi serwera aplikacyjnego,
- logi GC,
- logi aplikacji,
- logi dedykowanych appenderów, np. do integracji.
Analizę najlepiej wykonywać „kombajnem” typu ELK (ElasticSearch, Logstash, Kibana) wraz z ustawionymi alarmami (Elastalert) na nietypowe zdarzenia, np. zwiększona ilość występowania błędów w zadanej jednostce czas.
Oprócz samego rozwiązania technicznego, konieczne są ustalenia organizacyjne żeby zespół reagował na alerty i podejmował prace „pielęgnacji kodu”.
9. Dane testowe
Reprezentatywne i aktualne dane testowe w lokalnym środowisku developerskim znacząco ułatwiają wprowadzanie zmian i poprawek. Można stosować dwa podejścia:
- dane testowe reprezentujące specyficzne przypadki użycia,
- „prawdziwe” dane jako kopia z produkcji, odpowiednio zanonimizowane i uczyszczone wraz z procesem cyklicznego odświeżania.
10. Testy automatyczne
Testy automatyczne z definicji mają zastąpić żmudne ręczne przekliwanie całego systemu w poszukiwaniu błędów, które teoretycznie należałoby robić po każdej najmniejszej zmianie, aby zapobiec wprowadzeniu nowych błędów (regresji).
Dla aplikacji webowych w wersji minimalistycznej testy można wykonywać poprzez sekwencyjne pobieranie dowolnym narzędziem (np. curl) kolejnych adresów stron WWW lub z usług API i sprawdzać tylko czy nie zwracają kodu błędu. W bardziej zaawansowanych rozwiązaniach można jeszcze sprawdzić czy pobrana strona lub dane zawierają oczekiwane informacje, np. wysłane wcześniej dane, potwierdzania złożenia zamówienia, itp. Narzędzia typu Selenium pozwalają na wierniejsze testowanie działań użytkownika, symulując ruchy kursowa, klikanie linków i przycisków oraz wprowadzenie treści formularzy.
Najbardziej szczegółowe narzędzia do testów pozwalają na równoległe kontrolowanie nowej wersji aplikacji na środowisku testowym i aktualnej aplikacji na środowisku produkcyjnym i sprawdzanie czy wygląd kolejnych stron nie różni się ani o piksel.
Osobnym typem testowania są testy obciążeniowe (np. z użyciem Gatling), w ramach których generujemy sztuczne obciążenie poszczególnych elementów aplikacji (np. poszczególnych stron lub usług) i obserwujemy szybkość generowania odpowiedzi. Dla niezmiennych warunków środowiska wyniki kolejnych testów powinny być nie gorsze niż w poprzednich iteracjach.
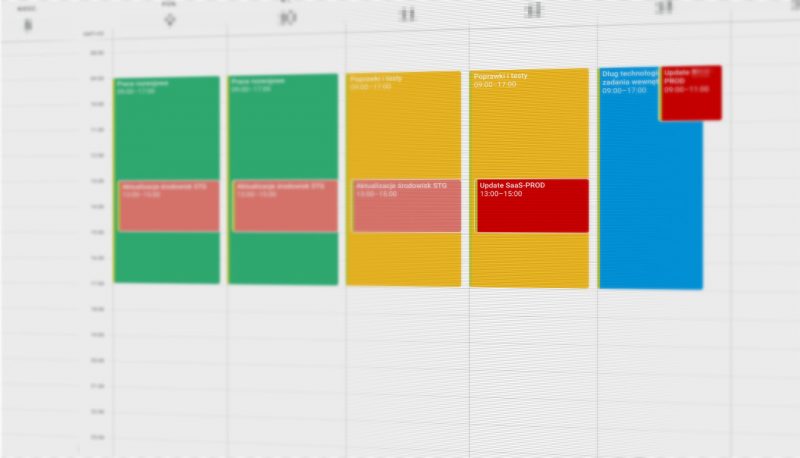
11. Organizacja prac i spotkań zespołu
Niezależnie od tego czy zespół pracuje w metodykach zwinnych (np. scrum) w sprintach czy w klasycznym projekcie z etapami, to pracy towarzyszą cykliczne spotkania i wydarzenia. Najlepiej je zorganizować przy pomocy współdzielonego kalendarza do którego wszyscy mają dostęp, a do poszczególnych wydarzeń są zapraszane te osoby które w nich uczestniczą. Typowymi wydarzeniami są:
- cykliczne spotkania planujące i podsumowujące sprint / etap,
- spotkania statusowe (także daily stand-up),
- zaplanowane aktualizacje środowisk,
- dyżury serwisowe,
- szkolenia,
- urlopy.
Dostępność wspólnego kalendarza pozwala na dostosowanie planów poszczególnych członków zespołu, potwierdzania obecności na spotkaniach oraz ułatwia współpracę z pracownikami zdalnymi, którzy łatwo mogą dołączać się do wspólnych spotkań.
12. Zasady komunikacji w zespole
Każdy zespół komunikuje się inaczej, z użyciem innych narzędzi (np. Jira, Slack, e-maile, telefon, itp.) oraz innych zasad. Żeby utrzymać komfort pracy trzeba jasno określić i spisać te zasady, tak aby nowi członkowie zespołu mogli się łatwo dostosować.
Przy projektach informatycznych korzysta się z narzędzi do zarządzania zadaniami (np. wspomniana JIra) i o ile ogólna zasada działania tego typu narzędzi jest taka sama, to w poszczególnych projektach mogą występować różne statusy i obiegi zadań (tzw. workflow). W związku z tym należy ustalić który status co oznacza, kto jest wtedy odpowiedzialny z wykonanie kolejnego kroku i jak należy się o tym informować aby zadania były bezzwłocznie podejmowane. W ten sposób unikniemy sytuacji że zadania nam się „gubią” i nikt się nimi nie zajmuje.
13. Harmonogram pielęgnacji i unowocześniania aplikacji
Nawet najnowocześniejsza aplikacja w momencie ukończenia projektu zaczyna zaciągać swój dług techniczny. Wynika to z szybkiego rozwoju technologii, ograniczonego okres wsparcia produktów firmy trzecich (np. serwery aplikacyjne, serwery baz danych) oraz faktu że w kończonym projekcie zawsze zostaje coś do poprawienia. Sztuka komfortowego wieloletniego utrzymania projektów polega na zdyscyplinowanym ewidencjonowaniu i planowaniu ulepszeń:
- aktualizacje wersji narzędzi i bibliotek np. update wersji Java, serwera aplikacyjnego, bazy danych,
- zmiany narzędzi pomocniczych, np. do budowania (Gradle), zarządzanie zmianami bazy danych (np. Flyway), itp.
- refaktoringi części aplikacji z użyciem nowszego frameworku,
- reimplementacja całej aplikacji przy okazji wykonywania dużych zmian funkcjonalnych.
Unowocześnianie stosu technologicznego, oprócz samej zalety korzystania z lepszych rozwiązań, ma też aspekt społeczno-edukacyjny – umożliwia członkom zespołu rozwój i naukę nowych technologii, co ma szczególne znaczenie w młodych zespołach.
14. Procedura przyjęcia nowego członka zespołu
Żeby przyjecie nowego członka zespołu nie dezorganizowało normalnych prac, oraz żeby nowa osoba szybko i bezboleśnie zapoznała się ze stosem technologicznym i sposobem pracy zespołu, warto taki proces spisać. Na ogół składa się on z:
- spotkań wprowadzających,
- procesu edukacyjnego: dokumentacja, szkolenia, książki, zadania wdrożeniowe,
- nadania uprawnień do repozytoriów, bazy wiedzy,
- założenia kont na poszczególnych środowiskach,
- udostępnienia haseł współdzielonych.
Więcej na ten temat pisałem we wpisie Checklista przyjęcia nowej osoby do zespołu technicznego.
15. Spotkania okresowe
Cykliczne spotkania okresowe stanowią ważny element budowania zespołu oraz rozwoju poszczególnych jego członków. Standardowym elementem takiego spotkania są:
- przekazywanie przez przełożonego pracownikowi opinii na temat jego pracy (na podstawie własnych obserwacji oraz zebranych uwag od innych osób współpracujących),
- zebranie opinii od pracownika na temat projektu, organizacji pracy zespołu i całej firmy,
- omówienie strategii rozwoju projektu i roli jaką pracownik ma w tym odgrywać,
- ustalenie osobistych celów dla pracownika na kolejny okres,
- przekazanie sugestii dotyczących rozwoju osobistego (np. rekomendowane książki, certyfikacje, konferencje, szkolenia, spotkania społecznościowe, itp.)
Podsumowanie
Mimo że większość opisywanych punktów wydaje się prosta i oczywista, to pilnowanie realizacji wszystkich z nich wymaga wiele dyscypliny. Problemem jest to, że z perspektywy interesariuszy biznesowych (klient, manager) większość z nich nie daje bezpośredniej wartości biznesowej, tzn. zmian aplikacji. Z tego względu zespół musi pamiętać o nich sam, oraz uzasadniać konieczność wykonywanych w związku z nimi prac równolegle do prac przynoszących wspomnianą „wartość biznesową”. Zaniedbanie tych aspektów prowadzi do szybkiego obniżenia komfortu pracy w zespole, w efekcie spadku efektywności i częstszych rotacji, a to z kolei przekłada się na trudność do dostarczaniem oczekiwanych przez interesariuszy wartości biznesowych.
O autorze
Marek Berkan: programista, entuzjasta tworzenia oprogramowania, zarządzania zespołami technicznymi. Prywatnie motocyklista, kolarz MTB, biegacz, żeglarz, rekreacyjny wspinacz, zamiłowany turysta. Witryny: google plus, facebook, twitter.
- More at
