

W ramach poszerzania wiedzy i przygotowania się do kolejnych spotkań e-point’owej Gildii Software Craftsmanship wybrałem do przeczytania książkę NoSQL. Kompendium wiedzy napisaną przez Pramod J. Sadalage’a i Martina Fowlera w 2013 roku.
Książka jest dobrze napisana i wystarczająco dobrze przetłumaczona na polski (chociaż próby lokalizacji przykładów danych i kodu są nieco dziwne i zawierają drobne błędy).
Celem książki jest wprowadzenie w tematykę baz NoSQL, wytłumaczenie przyczyn powstania, podstawowych kategorii i pokazanie która kategoria do jakich zagadnień się nadaje. Kierowana jest do osób bez doświadczenia i napisana przystępnym językiem, więc nadaje się zarówno dla studentów informatyki jak i osób z branży „dokształcających się” (jak ja). Jej przeczytanie pozwoli na ogólną orientacje i zrozumienie podstawowych elementów teorii, a także rozróżnianie przykładowych implementacji OpenSource i komercyjnych znanych na rynku. Pokrótce opisane zostały przykładowe implementacje OpenSource (Riak, MongoDB, Cassandra, Neo4J) z modelem danych, konfiguracją klastra i podstawowymi zapytaniami.
Książka jest relatywnie niedługa (168 stron), więc siłą rzeczy opisy poszczególnych baz są bardzo uproszczone i mają na celu pokazanie różnic, a nie są wyczerpującą dokumentacją, tej trzeba szukać w kolejnych bardziej szczegółowych pozycjach.
Koncepcja e-commerce na NoSQL
Mi najbardziej spodobał się rozdział „Poliglotyczne wykorzystanie magazynu danych” opisujący jak jedną aplikacje e-commerce (sklep internetowy) zdekomponować aby nie trzymać wszystkich danych w jednej bazie relacyjnej (jak robiliśmy przez lata) tylko poszczególne obszary wydzielić do źródeł NoSQL. Sądzę że ten przykład doskonale tłumaczy ideę tego typu podejścia i postanowiłem rozwinąć ją o jeszcze jeden element (SOLR – wspominany w książce, ale nieuwzględniony w oryginalnym schemacie).
Pomysł jest następujący:
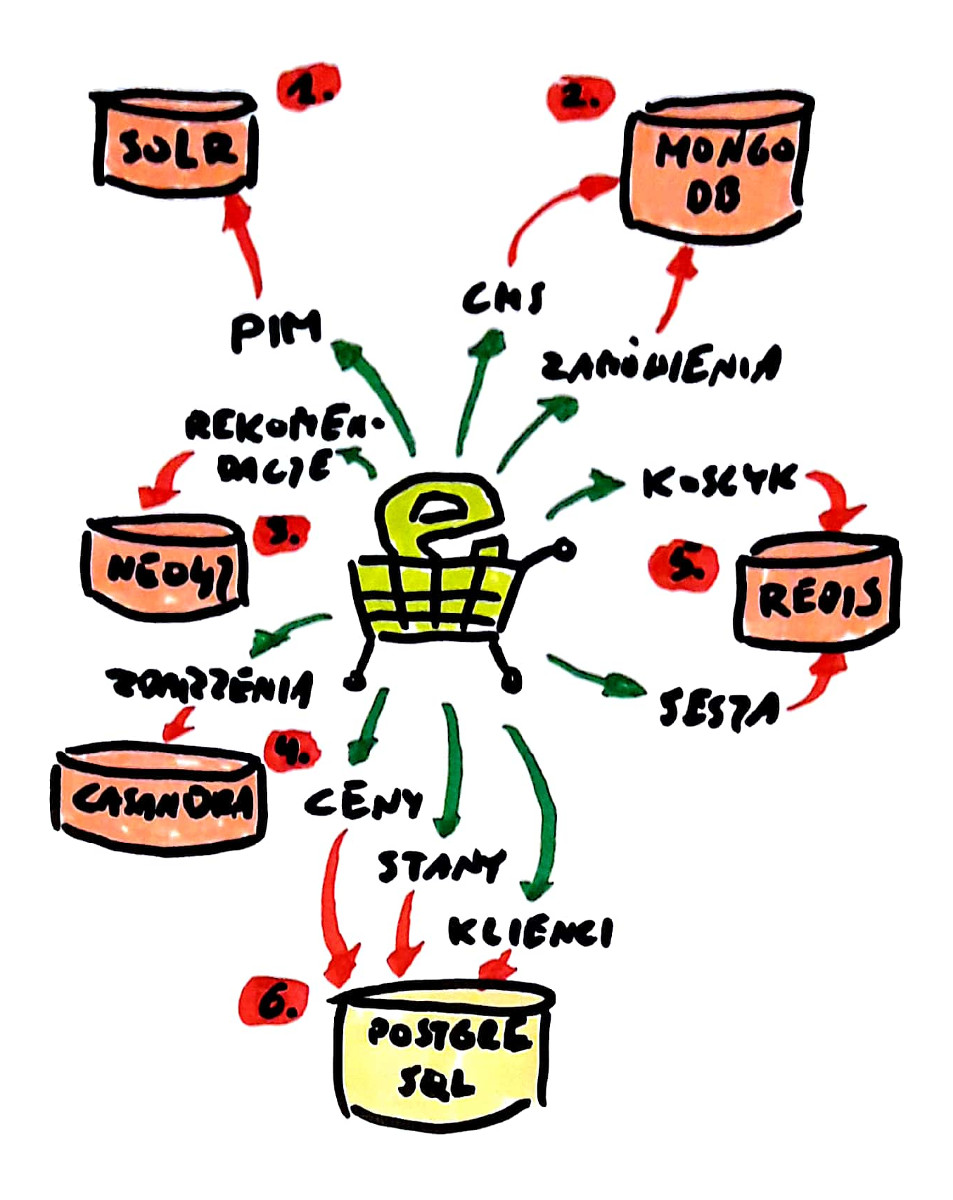
e-commerce na NoSQL
- Informacje o produktach (PIM – ang. Product Information Management) trzymamy w bazie dokumentów SOLR umożliwiającej wyszukiwanie pełnotekstowe oraz w oparciu o atrybuty (tzw. facety) powszechnie używane w sklepach internetowych. SOLR (czy podobny Elastic Search) i tak niemal zawsze towarzyszy bazie SQL z której importuje się dane (indeksuje) ale w zasadzie można byłoby z tego zrezygnować i pozostawić tylko taką bazę.
- Treści stron (CMS – ang. Content Management System) oraz złożone zamówienia można trzymać w bazie dokumentowej MongoDB. Mapowanie hierarchii layoutu i komponentów stron na relacje w bazie SQL jest przekleństwem architektów, za to dokument bez schematu idealnie pasuje do rozwiązania tego problemu. Podobnie z zamówieniami historycznymi – najczęściej w systemie e-commerce służą one wyłącznie do wyświetlania dla zalogowanego użytkownika, więc jest to określony agregat. Bardziej skomplikowane obliczenia, np. jaki produkt jest najczęściej zamawiany i tak robione są w zewnętrznych dedykowanych systemach analitycznych.
- Rekomendacje produktów typu „inni użytkownicy zamówili też…” robione są najczęściej przez dedykowane systemy, ale jeżeli już miałaby to robić nasza aplikacja, to może rozsądniejsze byłoby zastosowanie bazy grafowej, jak Neo4J.
- Zawartość koszyka i inne elementy sesji użytkownika, których nie możemy trzymać wyłącznie w pamięci, najlepiej umieścić w prostej bazie danych klucz-wartość, jak np. Redis, jako wielki, szybki i trwały cache.
- Informacje o zdarzeniach (zachowaniach) użytkowników, jak przeglądanie kategorii czy produktu, dodanie do koszyka, wybór opcji dostawy czy płatności, oraz ostatecznie złożenie zamówienia, mogłyby być umieszczane w bazie „rodziny kolumn” jak Cassandra.
- Pozostałe dane, jak ceny, stany magazynowe i podstawowe dane klientów mogłyby zostać w klasycznej relacyjnej bazie danych, np. PostgreSQL.
Taki katalog źródeł danych jest oczywiście nieakceptowalny w „tanich” wdrożeniach, jednak przy dużych, gdzie ilość danych i skalowalność odgrywa istotną rolę, jest już warto rozważenia. Jeszcze kilka lat temu zarządzanie tak dużą infrastrukturą (każdy z zaznaczonych wyżej elementów powinien składać się z 3-5 węzłów) byłoby przekleństwem każdego administratora. Ale obecnie, przy popularyzacji konteneryzacji (Docker) i automatyzacji konfiguracji i deploymentu wydaje się być możliwe do realizacji.
Przykład jest czysto teoretyczny ale wydaje mi się że dobrze oddaje koncepcję baz NoSQL prezentowaną w książce: dla każdego typu zagadnienia trzeba znaleźć najlepiej pasujący magazyn danych.
Podsumowanie
Reasumując, książkę polecam wszystkim nie mającym wcześniej kontaktu z bazami NoSQL lub chcącymi uporządkować sobie wybiórczą wiedzę w tym temacie.
O autorze
Marek Berkan: programista, entuzjasta tworzenia oprogramowania, zarządzania zespołami technicznymi. Prywatnie motocyklista, kolarz MTB, biegacz, żeglarz, rekreacyjny wspinacz, zamiłowany turysta. Witryny: google plus, facebook, twitter.
- More at
